Data is the focal point of modern software-intensive systems. From the simplest mobile applications to the most complex enterprise and military system-of-systems, effective data management is of critical importance to the system’s success as well as one of the major cost drivers. Not surprisingly, this has lead to a plethora of heterogeneous and distinct database management technologies, platforms, languages, and paradigms.
The power of a database does is not found solely in the actual data. Today’s sophisticated database management systems (DBMS) are often just as complicated as the applications they serve; for example, stored procedures (customized programming inside the database) and conditional triggers (automatic actions on certain fields) are two powerful techniques that reduce workload on the main application. The ecosystem of cutting-edge database products is expanding quickly and constantly. Quandary Peak has the experts and experience to help you understand where database technology fits into your case.
What We Do
Quandary Peak experts can assist you in:
- Determining the structure of a computer database system regardless of the implementation technology (SQL, XML, or NoSQL).
- Analyzing computer database accesses to determine who, when, and how accessed the data.
- Determining the root cause of data loss or corruption.
- Assessing the quality of the implemented database application, including assessment of the database’s scalability, availability, consistency, and security.
- Compiling meta-information about the database in support of litigation claims (e.g., a patent may define a specific type of a unique identifier that is stored as a string).
What We Know
- E-R modeling, database normalization
- MySQL, Microsoft SQL Server, Oracle, PostgreSQL, IBM DB2, IBM Informix, SQLite
- Microsoft Access, Oracle Forms, Kexi
- ODBC, JDBC, OLE DB, ADO.NET
- DatabaseSpy, dbTrends, Oracle SQL Developer, phpMyAdmin, SQuirreL SQL, Toad
- XML, XPath, XSLT, XQuery
- Distributed databases, duplication, replication, caching
- Apache CouchDB, Couchbase Server, MongoDB, Oracle NoSQL Database
- Apache Cassandra, Dynamo, Project Voldemort, BigTable, BerkeleyDB, Apache Hbase
Our computer database experts have a deep understanding of computer database technology.
Computer databases come in various shapes and sizes. Most commonly, we hear the term relational database and the closely associated relational database management system (RDBMS) to refer to a data store. However, a new breed of databases, referred to as NoSQL databases, is making new waves in the field of database technology. NoSQL databases are radically different from relational databases in the way data is viewed, queried and stored. Our experts are highly knowledgeable in both relational and NoSQL databases.
Relational Databases
E. F. Codd originally proposed the relational database model, in 1970, while working at IBM. Prior to that, data was commonly stored in flat files and was mostly cumbersome to query to get the information needed by the organization. By 1980 SQL became the standard query language for querying relational databases and the RDBMS soon became the dominant form of data storage.
In relational databases, data is organized into one or more tables (or relations) of rows and columns, with a unique key for identifying each row. A table corresponds to a particular entity (e.g., User) and each row represents information about a particular instance of the entity (e.g., a specific User).
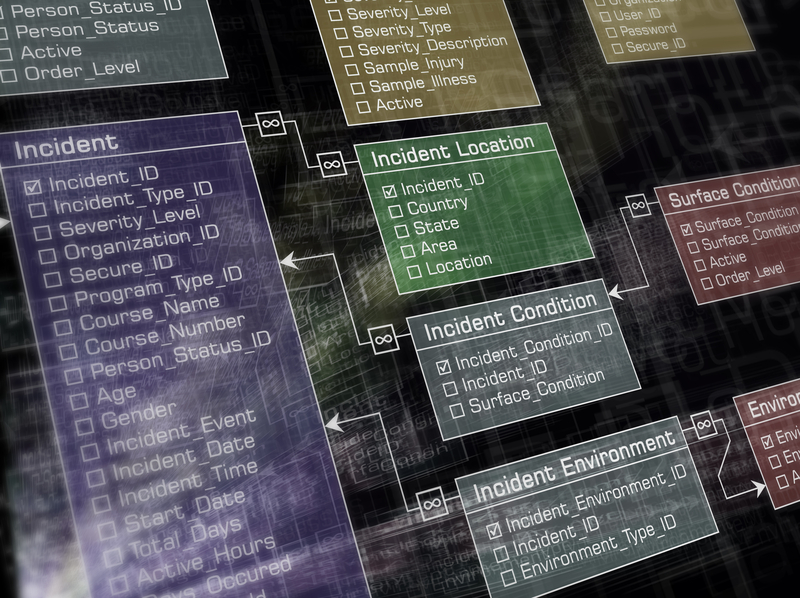
Database expert witnesses analyze schemas and code.
Rows in a table can be linked to rows in other tables by storing the unique key of the row to which it should be linked (i.e., a foreign key). Data relationships of arbitrary complexity could be represented using this simple set of concepts. Querying the data involves (possibly) navigating multiple tables, which can be a performance bottleneck. However, the relational model lends itself to arbitrary queries without much forethought. Almost always, most of your data would be a good fit for the relational model. MySQL and PostgreSQL are examples of open source databases, and Oracle and Microsoft SQL Server are proprietary implementations of the relational model. All databases implement the SQL standard and provide support for transactions, and with the exception of MS-SQL, are also cross-platform.
NoSQL Databases
For more than two decades, relational databases were the dominant data store for any enterprise grade application. However, the need for handling extremely large volumes of data, especially spread across commodity hardware, forced a fundamental shift from the relational model. Different types of computer databases commonly referred to under the banner of NoSQL are giving the relational databases a run for their money. There are many variants of NoSQL databases – key-value stores, document databases, column-family databases, graph databases etc., each having appropriate use-cases for their deployment. However, we are yet to understand them as well as we have understood the relational paradigm. Below we list the most commonly encountered NoSQL databases.
Key-Value databases: The data is stored and referenced by a unique key. However, this data is mostly opaque to the computer database. That is, one cannot usually query against the value of the key. The data could be absolutely anything but the underlying storage engine is agnostic to the contents. Its primary purpose is to store the data referenced by a particular key and retrieve it when queried for. It’s ideal for storing session information or storing the list of items in a user’s shopping cart for an ecommerce website. BerkleyDB, Riak, Redis etc., are all examples of key-value databases.
Document Databases: The computer database stores and retrieves documents in multiple formats like JSON, XML, BSON etc. These documents are usually self-describing, hierarchical tree structures that can take on a multitude of values. If your data can be organized as a table of contents of a book, with perhaps multiple child levels, it is probably a good candidate for a document database. MongoDB and CouchDB are the most popular document databases currently in use.
Column-Family Databases: Column families are groups of related data that is often accessed together e.g., when accessing a User’s information, we would often access their Profile information at the same time. These databases store data in column families as rows that have many columns associated with a row key. Thus a particular row can have multiple columns, and each row can have a different set of columns. Given our familiarity with the relational model, it takes a while to get used to the unnatural way of thinking in terms of column families. If you are to lay out your data in a tabular structure and each row is sparsely populated, your data is probably a good candidate for column-family databases. Cassandra, Amazon SimpleDB and HBase are the most well known members of the column-family databases.
Graph Databases: The primary function of these computer databases is to store a multitude of relations among entities to make relational queries as trivial as possible, without the overhead of multi-table navigation, as in a relational database. For example, queries like “show me a list of restaurants all my friends have been to in the last month” are well suited for graph-databases. If your data has a lot of relationships between multiple entities, and the queries are based on the existence (or absence) of these relations, then your data is a good candidate for graph databases. Neo4j is a good example of such a database.
Datastores: Many large-scale software systems demand saving data locally and then resuming state across sessions. The primary solution for this problem is using SQLite or another plugin, but these technologies do not provide adequate performance in some cases. For example, SQL is cumbersome and non-intuitive for many web and smartphone applications. For these types of applications, a datastore provides a superior solution. Datastores are focused on atomic transactions, high availability of reads and writes, strong consistency of reads and ancestor queries, and eventual consistency for all other queries. Datastores hold data objects (entities) along with their properties, replicate them across multiple data centers, and offer a high level of availability for data manipulation operations.