Software maintenance costs result from modifying your application to either support new use cases or update existing ones, along with the continual bug fixing after deployment. As much as 70-80% of the Total Ownership Cost (TCO) of the software can be attributed to maintenance costs alone!
Software maintenance activities can be classified as [1]:
- Corrective maintenance – costs due to modifying software to correct issues discovered after initial deployment (generally 20% of software maintenance costs)
- Adaptive maintenance – costs due to modifying a software solution to allow it to remain effective in a changing business environment (25% of software maintenance costs)
- Perfective maintenance – costs due to improving or enhancing a software solution to improve overall performance (generally 5% of software maintenance costs)
- Enhancements – costs due to continuing innovations (generally 50% or more of software maintenance costs)

Since maintenance costs eclipse other software engineering activities by large amount, it is imperative to answer the following question:
How maintainable is my application/source-code, really?
The answer to this question is non-trivial and requires further understanding of what does it mean for an application to be maintainable? Measuring software maintainability is non-trivial as there is no single metric to state if one application is more maintainable than the other and there is no single tool that can analyze your code repository and provide you with an accurate answer either. There is no substitute for a human reviewer, but even humans can’t analyze the entire code repositories to give a definitive answer. Some amount of automation is necessary.
So, how can you measure the maintainability of your application? To answer this question let’s dissect the definition of maintainability further. Imagine you have access to the source code of two applications – A and B. Let’s say you also have the super human ability to compare both of them in a small span of time. Can you tell, albeit subjectively, whether you think one is more maintainable than the other? What does the adjective maintainable imply for you when making this comparison – think about this for a second before we move on.
Done? So, how did you define maintainability? Most software engineers would think of some combination of testability, understandability and modifiability of code, as measures of maintainability. Another aspect that is equally critical is the ability to understand the requirement, the “what” that is implemented by the code, the “how”. That is, is there a mapping from code to requirements and vice versa that could be discerned from the code base itself? This information may exist externally as a traceability document, but even having some information in the source code – either by the way it’s laid out into packages/modules, naming conventions or having READMEs in every package explaining the role of the classes, can be immensely valuable.
These core facets can be broken down further, to gain further insight into the maintainability of the application:
- Testability – the presence of an effective test harness; how much of the application is being tested, the types of tests (unit, integration, scenario etc.,) and the quality of the test cases themselves?
- Understandability – the readability of the code; are naming conventions followed? Is it self-descriptive and/or well commented? Are things (e.g., classes) doing only one thing or many things at once? Are the methods really long or short and can their intent be understood in a single pass of reading or does it take a good deal of screen staring and whiteboard analysis?
- Modifiability – structural and design simplicity; how easy is it to change things? Are things tightly or loosely coupled (i.e., separation of concerns)? Are all elements in a package/module cohesive and their responsibilities clear and closely related? Does it have overly deep inheritance hierarchies or does it favor composition over inheritance? How many independent paths of execution are there in the method definitions (i.e., cyclomatic complexity)? How much code duplication exists?
- Requirement to implementation mapping and vice versa – how easy is it to say “what” the application is supposed to do and correlate it with “how” it is being done, in code? How well is it done? Does it need to be refactored and/or optimized? This information is paramount for maintenance efforts and it may or may not exist for the application under consideration, forcing you to reverse engineer the code and figure out the ‘what’ yourself.
Those are the four major dimensions on which one can measure maintainability. Each of the facets can (and is) broken down further for a more granular comparison. These may or may not be the exact same ones that you thought of, but there will be a great deal of overlap. Also, not every criterion is equally important. For some teams, testability may trump structural/design simplicitly. That is, they may care a lot more about the presence of test cases (depth and breadth) than deep inheritance trees or a slightly more tightly coupled design. It is thus vital to know which dimension of maintainability is more important for your maintenance team when measuring the quality of your application and carry out the reviews and refactoring with those in mind.
The table below, towards the end of the article, shows a detailed breakdown of the above dimensions of maintainability and elaborates on their relevance to measuring the quality of the source code [2]:
- Correlation with quality: How much does the metric relate with our notion of software quality? It implies that nearly all programs with a similar value of the metric will possess a similar level of quality. This is a subjective correlational measure, based on our experience.
- Importance: How important is the metric and are low or high values preferable when measuring them? The scales, in descending order of priority are: Extremely Important, Important and Good to have
- Feasibility of automated evaluation: Are things fully or partially automatable and what kinds of metrics are obtainable?
- Ease of automated evaluation: In case of automation how easy is it to compute the metric? Does it involve mammoth effort to set up or can it be plug-and-play or does it need to be developed from scratch? Any OTS tools readily available?
- Completeness of automated evaluation: Does the automation completely capture the metric value or is it inconclusive, requiring manual intervention? Do we need to verify things manually or can we directly rely on the metric reported by the tool?
- Units: What units/measures are we using to quantify the metric?

There is no single metric that can accurately capture the notion of maintainability of an application. There exist compound metrics like maintainability index (MI) that help predict the maintainability of the application using the Halstead Volume, Cyclomatic Complexity, Total SLOC (source lines of code) and Comments Ratio [3]:
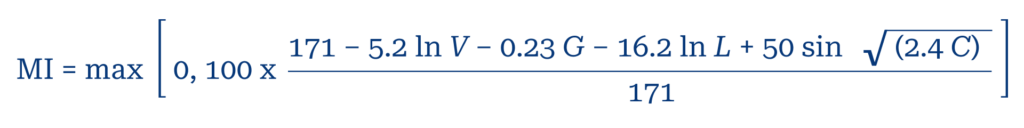
Key:
- V is the average Halstead Volume per module
- G is the average Cyclomatic Complexity per module
- L is the average number of Source Lines of Code (SLOC) per module
- C is the average number of comment lines per module
Note: some variants of the formula suggest using ‘sum total values’ instead of averages.
The use of this metric is debatable but could be used in conjunction with the above metrics or your team could create a compound metric based on the above dimensions! As long as the metric makes sense to your team and your organization you’re free to create your own, albeit meaningful, metrics.
It is wise to keep tracking the relevant metrics at various anchor-point milestones and throughout the development life-cycle, as well as having periodic code reviews to ensure that code quality is high. As you can see one can’t (and shouldn’t) solely rely on the metrics output by automated tools. Care must be taken to interpret the value of the metrics and use them to guide the refactoring of the code base.
I hope this article proves useful to help expand your mind on what all to look at when measuring maintainability along with throwing light on the non-triviality of measuring the quality of source code. For our next article we’ll dive in to concrete examples of how we can measure the modifiability of an example code base using tools like Google’s Code Pro Analytix and SourceMonitor and see how to interpret their results to write better and cleaner code.



