Every software expert at Quandary Peak regularly reads and analyzes large volumes of source code, and while understanding the specific programming language can help, it’s not the only skill we bring to a project. Knowing the unique qualities and nuances that apply to programming code can be the difference between winning and losing a trial. In this eight-part series of posts I’ll describe a few of the unintuitive aspects of source code that experts have to keep in mind when working on your case.
Source Code Never Runs
Like attorneys, software programmers are in the business of technicalities, where small distinctions can sometimes make a big difference. This is particularly important in software patent cases, which can often hinge on very minor, esoteric aspects of code (very minor to a non-computer-scientist, at least.) One of those potential trivialities is the distinction between the code written by programmers and what instructions the computer executes. As we shall see, virtually all the code written by programmers never runs on any computer. How is this possible? To explain this apparent contradiction, we need a bit of history.
Computers Prefer Numbers
Alan Turing was an early computer scientist who was instrumental in the Allies’ World War II victory. Seventy years ago he theorized a device, now called a Turing machine, that could read and write limitless numbers on an endless paper tape, to complete arbitrary mathematical tasks.
Later, in the 1970s, the first build-it-yourself home computer, the Altair 8800, was great at mathematical tasks, but not so great at inputting them: it had no keyboard. To enter a number into the Altair, you had to look up which switch positions on the front panel represented the number you wanted to enter, flip the switches accordingly, then flip a final switch to commit the number into memory.

Today, contemporary microtransistor-based CPUs are very good at reading and writing numbers… countless quadrillions of zeros and ones. There’s nothing a digital computer does better than process those two digits.
People Prefer Words
What all these systems, old and new, have in common is that they all process numbers that represent the programmer’s wishes. But when it comes to expressing ideas, humans find numbers unwieldy; we prefer using words. For example, this is who I work for, in English (preferred by me) and binary (preferred by my computer):

Clearly, it’s impossible for a person to manage the dizzying combinations of zeros and ones to program a computer in its native tongue. So programming languages (like HTML, Javascript, Ruby, C, Visual Basic, Fortran, PHP, and many others) were developed to allow people to instruct computers what to do more easily. Using these programming languages, computer programs could now be written and read by a normal person.
But digital computers remain notoriously inflexible. The program may be written in a language a person can read, but what’s readable to a person is unusable to a computer. What’s needed is a way to convert the program (which people understand) into instructions (which the computer understands.)
Compilers Translate Source Code
This converting is performed by a specialized program called a software compiler. Essentially, a compiler reads the program written by a human being and “translates” it into the ones-and-zeros the computer understands. After the compiler has read all a program’s source code, it produces a binary file which can be executed by the processor. This binary file is the icon you see on your desktop; when you double-click it, the computer executes the instructions stored within. Without some kind of compilation step, no software program can run.
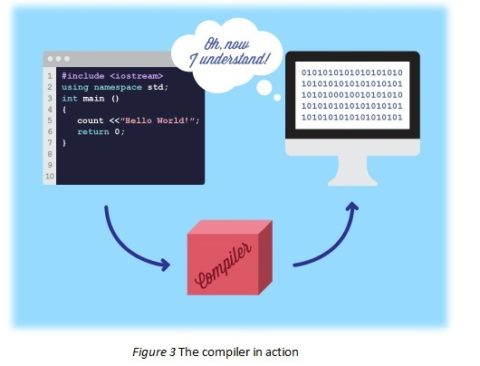
What this means is that the source code of a program is never used directly by the computer. All source code is rewritten by the compiler into a set of binary instructions that are a proxy for the source code; and those translated binary instructions are used by the computer. Source code itself never runs, because computers can’t understand it.
Understanding technical concepts like these can be essential to the success of your software-related case. If you don’t know the difference between Prolog and a server log, contact us for a free consultation.


